I recently attended ICLR 2018, as I had a workshop article accepted. Please, consider taking a look: A differentiable BLEU loss. Analysis and first results.
This was the first time I attended a conference, so I tried to learn as much as I could. These are some random notes about how the conference works and what people talked about.
How the conference works
ICLR is an artificial intelligence conference that uses a double-blind peer review process via OpenReview. Its format has changed a lot since its creation in 2013; here I comment on its format for 2018.
ICLR submissions are submitted under two different tracks: conference track and workshop track. The submissions accepted to the conference track appear in the conference proceedings while the conferenfe track articles are non-archival. The former usually has its deadline in late October while the Workshop track deadline is after the acceptance decissions for the Conference track are out.
Submissions to the Conference track can either be accepted, rejected or proposed for the Workshop track (i.e. automatic acceptance at the Workshop track if the authors present it there). Papers accepted for the Conference track must present a poster and the top ones also have an oral presentation. Papers submitted to the Workshop track can be accepted (either automatically for papers submitted to Conference that got acceptance to Workshop, or because they were accepted as part of the Workshop track review process) or rejected. Accepted Workshop papers must present a poster. You can find acceptance rates from previous years on the internet.
The conference takes place during 4 days. Each day there are some invited talks, a few oral presentations and poster sessions (in the morning and in the afternoon). Each accepted paper is assigned a poster session. During it, the author(s) stand next to their poster and explain their article to attendees that show interest in it. There are also company booths for promotion and hiring purposes.
What people talked about
My research is about Neural Machine Translation and how to induce prior linguistic knowledge into translation models. The things listed in this post are those that caught my interest and might be very biased toward my interests and previous experiences.
Language Modeling and Machine Translation
There were not a lot of articles in natural language processing, but there were some very interesting ones.
In my opinion, the most interesting article on Language Modeling was Breaking the Softmax Bottleneck, which reformulates LM as a matrix factorisation and identifies a that the rank of the result of the softmax is much lower than it would be needed for language modelling, and proposes a mixture of softmaxes that palliates such a problem effectively. In a conversation with the authors, they expressed their reserves in the effectiveness of their method when applied to neural machine translation, as the matrix factorisation formulation was not suitable in that case. This article built their LM on the sota LM implementation from Regularizing and Optimizing LSTM Language Models.
The most remarkable articles about Neural Machine translation were in my opinion the parallel submissions about Unsupervised Machine Translation by the University of the Basque Country (Unsupervised Neural Machine Translation) and Facebook (Unsupervised Machine Translation Using Monolingual Corpora Only). Both propose similar ideas: using multi-task learning with (denoising) auto-encoding and backtranslation as subtasks, being the main difference the fact that the latter relies on adversarial training to align internal representations while the former relies on pre-computed cross-lingual word embeddings (also created from monolingual data).
Generative Adversarial Networks
Since they were proposed in 2014, GANs have been widening their adoption and increasing their momentum year after year. In ICLR 2018, despite not being a lot of GAN papers, there were enough to make me think that GANs are going remain as one of the main research topics in deep learning at least for a few more years.
Morning oral presentations from day #1 were devoted to GANs. One of them impressed me, not only because of its amazing results but also because of the presentation style. It was the talk by Tero Karras from Nvidia about progressively growing GANs. His slides had fully automatic slide transitions (he did not press any button) and he was giving his speech as the slides were transitionining with perfect timing and using a was super calmed and clear discourse.
The posters about GANs I liked most were MaskGAN, Boundary Seeking GANs and Unsupervised Cipher Cracking Using Discrete GANs , all of them attempting to apply GANs to discrete sequences.
Though not about GANs, there was an intriguing workshop paper proposing a technique called Non-Adversarial Matching that aims at tasks similar to those addressed with CycleGANs but without needing adversarial training.
Graph Neural Networks
Several articles where about graph neural networks, both applied to supervised and reinforcement learning. It seems more and more people want to exploit graph structures in their problems. The article I liked most was Graph Attention Networks, which proposed a self-attention mechanism over graph structures.
A special mention is the application of neural networks for graph generation in computational chemistry, like the Syntax-Directed Variational Autoencoder for Structured Data, which externalises the generation itself to an external formal grammar.
Deep RL and Policy gradient methods
After the success of AlphaGo, the RL trend went up. However, the need for extensive hyperparameter search made it not permeate much to universities where you cannot afford having hundreds of GPUs computing during weeks to train a model, even though Population-Based Training has reduced notably the amount of needed processing.
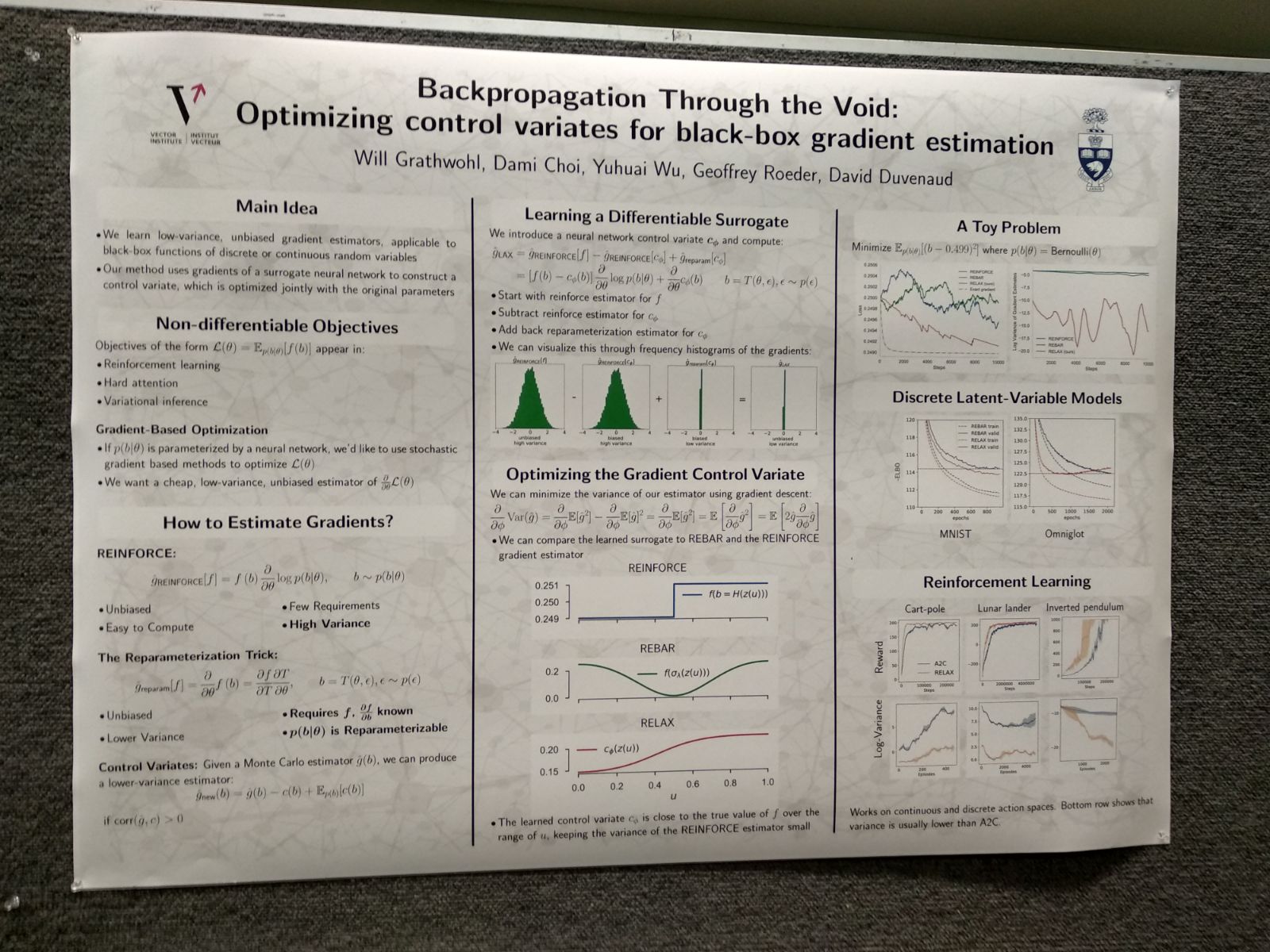
An article I liked was Backpropagation through the Void: Optimizing control variates for black-box gradient estimation. It proposes an unbiased gradient estimator for stochastic nodes in a computational graph, like REINFORCE but with a control variate, with much better results than REBAR.
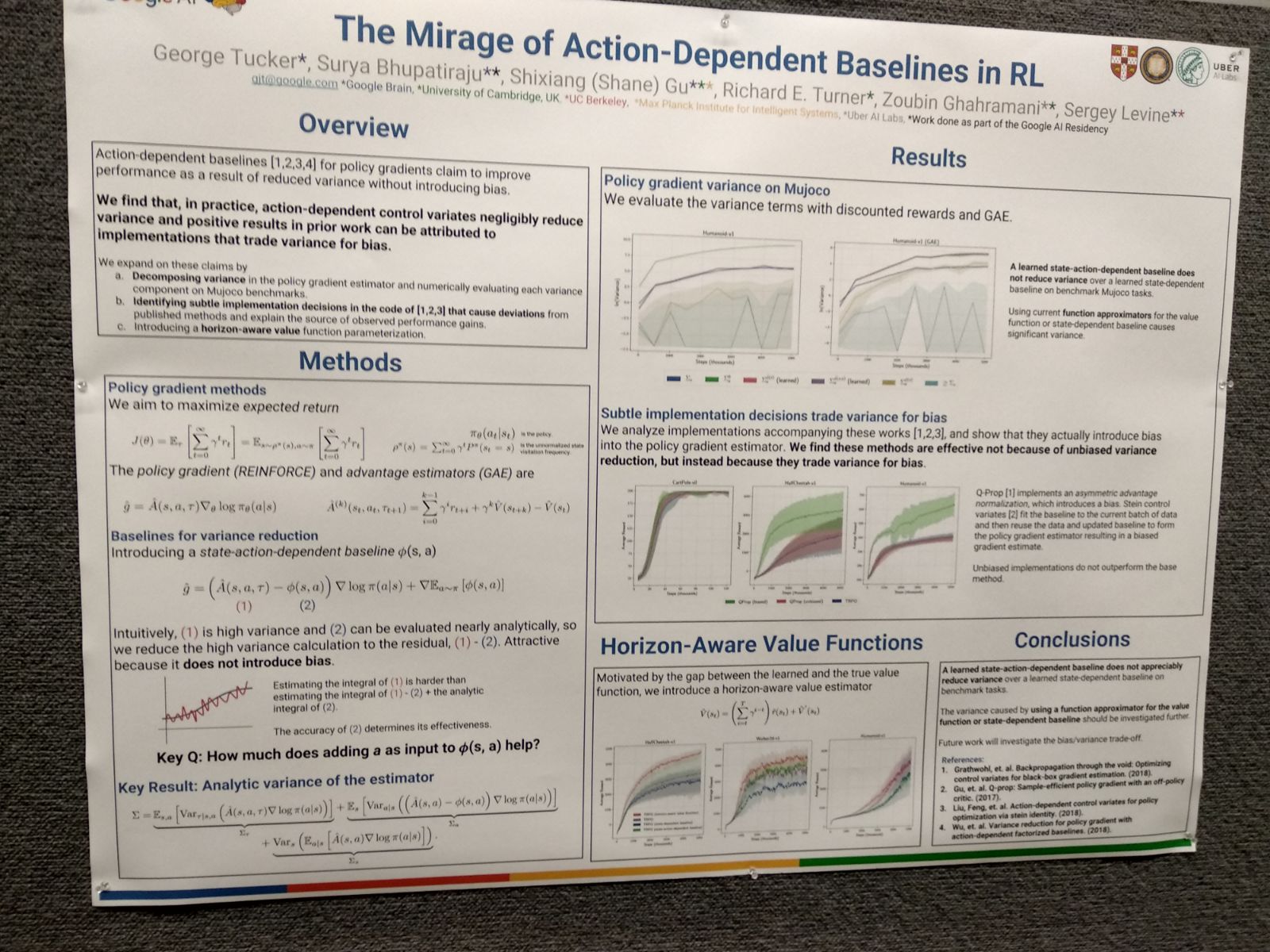
Apart from that one, there were other articles proposing strategies to reduce the variance of gradient estimators by defining baselines and control variates, including an oral presentation. However, one of the most interesting articles on that topic to me was workshop paper The Mirage of Action-Dependent Baselines in Reinforcement Learning, which finds that RL action variance reduction algorithms from the literature (and also some of the articles presented at ICLR 2018) are subtly wrong in their claims, as they don’t reduce variance but trade it for bias due to implementation bugs. Note that this conclusion only refers to action-dependent variance reduction.
Reproducibility
If you have done deep reinforcement learning, you probably experienced yourself that algorithms which on paper are exceedingly performant, present very poor convergence and are very sensible to hyperparameter selection. In her invited talk, Joelle Pineau talked about this, with references to her previous work in (Henderson et al., 2017).
Problems in reproducibility of scientific claims in machine learning seem to be not restricted only to deep RL, but to be part of a general reproducibility crisis. In order to mitigate it, she advocated for releasing source code and being fair when reporting results (e.g. not reporting only the best top K performant runs of a deep RL algorotithm, as they are evidently biased).
Part of her efforts to increase awareness about lack of reproducibility were poured on the ICLR 2018 Reproducibility Challenge that she coordinated this year. Some of the participants engaged in useful discussions with the authors of the articles they were trying to reproduce and led authors to improve on the clarity of their texts.
Source code synthesis and related tasks
There were several articles about source code synthesis and other tasks related to source code, like bug detection based on graphs. Here you can find a blog post devoted to this subset of ICLR 2018 papers.
Meta-learning and Architecture Search
It is totally unrelated to my research area, but I had the impression that, despite being very incipient yet, the interest in meta-learning and architecture search has increased a lot and that it is going to become a hot topic in the upcoming years.
Random Pictures of Posters
Finally, this is a random selection of pictures of posters I took at the conference:



Shameless self promotion…this is my poster: