I recently attended the Conference of the European Association for Machine Translation, EAMT 2018. Before this conference I had only attended ICLR, which is an AI conference focused on representation learning, irrespective of the specific task or paradigm (RL, GANs, NLP, images, etc). On the other hand EAMT is purely machine translation-focused.
This year EAMT took place over three days. The first day was focused on research (mostly academia), the second day on products and projects (industry) and the third one on translators (translators track).
One of the recurring topics was translation quality evaluation techniques. Despite BLEU being the dominant automatic measure and that to some degree it is correlated with human judgement, it is clear that the machine translation community is longing for a more grounded quality evaluation measure. Barry Haddow gave a talk about the WMT competition, and commented on how, apart from automatic measures, they use human-driven evaluation. They previously used human-driven relative ranking but now they resort to direct assessment (human evaluator assigns a mark between 0 and 100 with their judgement about the degree in which the translation adequately expresses the meaning of the reference translation, without ever seeing the source sentence).
A piece of research that had already caught my attention and that was presented at EAMT was Investigating Backtranslation in Neural Machine Translation. It explores the use of back-translation as a means to improve translation performance. Back-translation consists in: you want to train a language direction a ➝ b and you don’t have much parallel data but you have a lot of monolingual data in the target language b, so what you do is training an auxiliary translation system on the b ➝ a direction, and you create a synthetic parallel corpus by using your auxiliary system on your monolingual data. You now add your synthetic data to the original parallel data you had an voilà, you can train your a ➝ b system on a lot of real + synthetic parallel data. This is a practice that most groups and companies seem to be applying nowadays, as evidenced by the WMT 2018 news translation task system brief descriptions.
My company, Lucy Software, has been devising Rule-based Machine Translation (RBMT) systems for over 30 years. To my delight, at EAMT I got the confirmation that RBMT systems are still relevant nowadays, especially for low-resource morphologically-rich agglutinative languages with flexible word order, like Basque, Turkish or Kazakh. My main line of research at Lucy consists in hybridizing RBMT and NMT to leverage the large amount of formalized linguistic knowledge in our rule-based systems in the form of monolingual and bilingual lexicons and grammars for source language analysis, source to target transfer and target language generation. Confirming that the linguistic knowledge in rule-based systems is crucial for some language pairs encourages me to pursue my RBMT-NMT hybrid and to test it on such type of languages.
As a side note, be aware that using BLEU to assess the performance of an RBMT system in comparison with SMT or NMT is unfair. This quality evaluation measure compares ngram-wise the translation against a reference human translation, normally taken from a holdout set from a larger training corpus. The translations by SMT and NMT systems are expected to be similar to the reference. RBMT translations are not necessarily so similar to the references. Therefore, comparing RBMT against SMT and NMT on the basis of BLEU scores is not a sensible practice. Reviewers of the world, please take this into account when you ask article authors for BLEU scores.
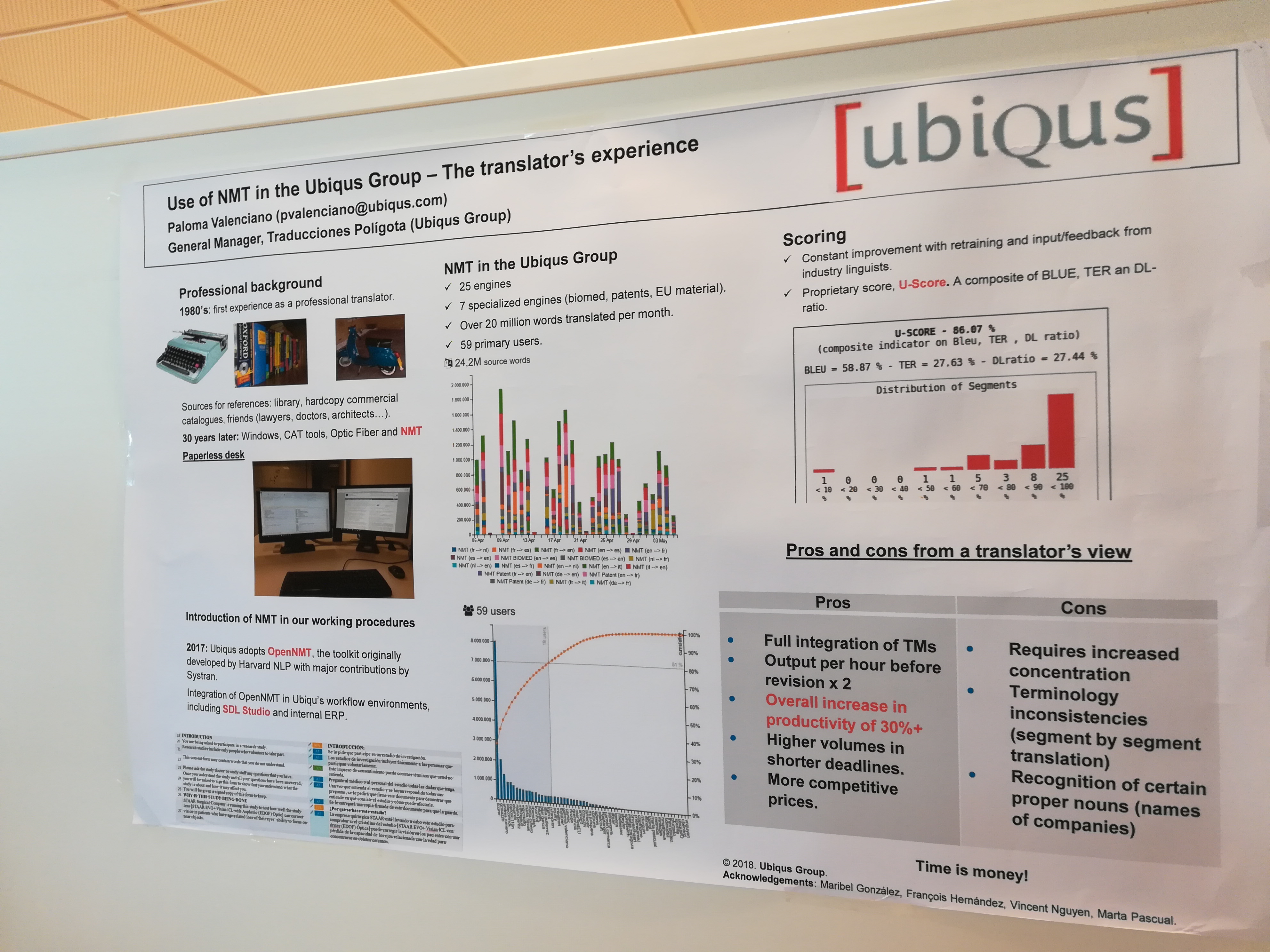
In the last years, the work of many human translators has shifted from pure translation to post-edition of machine translations due to the the increasing quality in machine translations. However, post-edition work is much less rewarding to them, and it is paid less. It is no secret that those human translators are worried about how MT may affect their work in the future, and even fearing that its quality may reach the point where there is no space for human translators anymore. With the newly introduced translators track, this year EAMT conference gave the machine translation community the opportunity to interact with human translators to get direct insight on how they feel about that and to try to find better synergic workflows involving MT and human translators. One of the conclusions of the translators was specially interesting: as NMT translations are very very fluent, post-editors need to pay more attention (i.e. devote more time) than with SMT not to overlook problems in the translated sentence.
Random Pictures of Posters
Finally, these are some posters that got my attention at the conference: